A unified perspective of RLHF
Last updated on July 1, 2025 pm
Currently popular RLHF Method
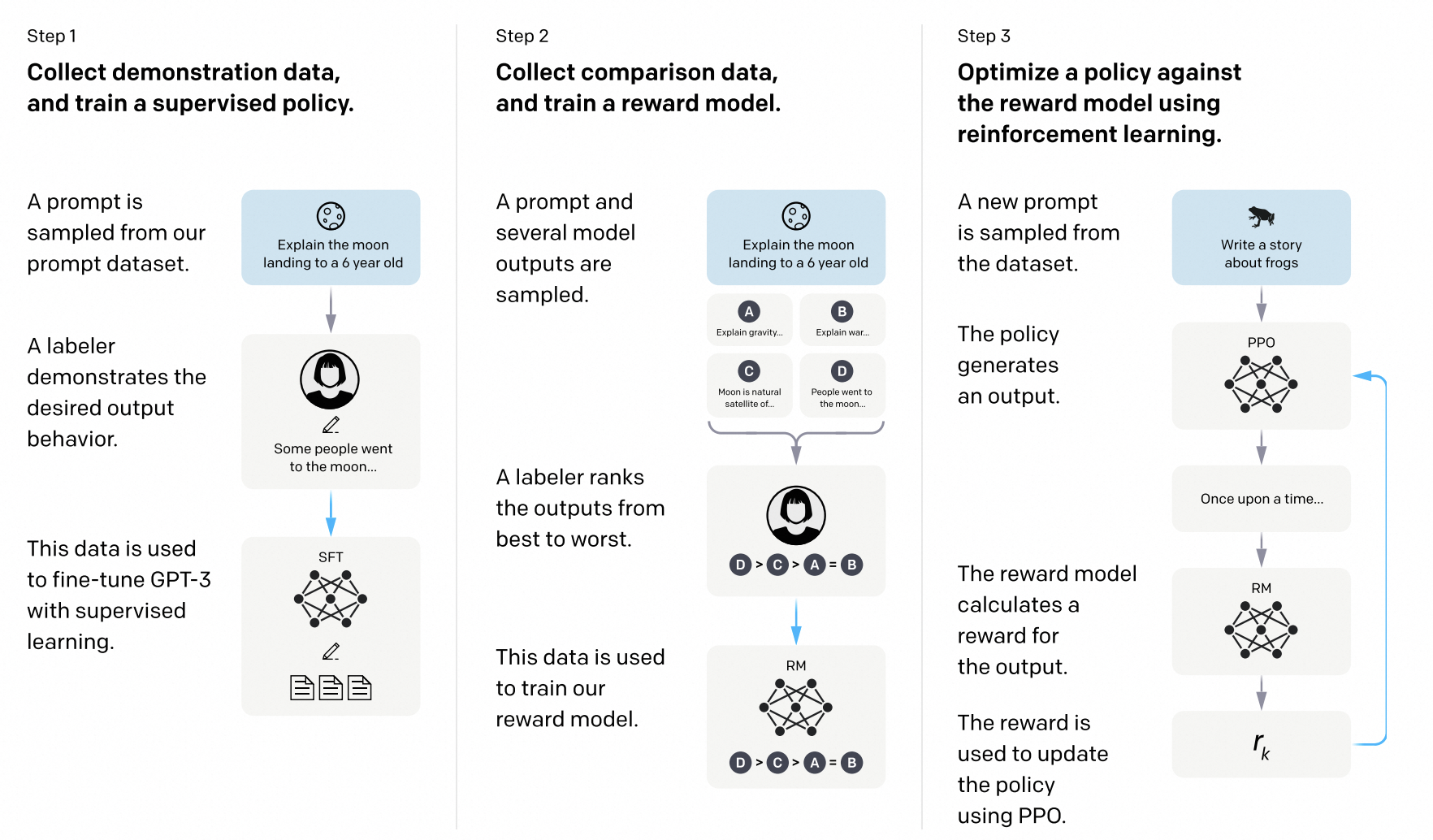
To this day,the post-training diagram for LLMs is still CPT, SFT and RLHF. There are no signs that this diagram will change currently. Focusing on RLHF, I will attempt to provide a comprehensive review, summary and future outlook in the following, in order to clarify its development path and hopefully gain some interesting insights.
Preliminaries
Potential-Based Reward Shaping (PBRS)
Definition
A shaping reward function is potential-based if there exists such that:
for all .
PBRS cleverly introduces the concept of potential, guiding the agent to search more quickly in the state space without altering the optimal policy of the original problem.
Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping
Policy Gradient Algorithm
As a reinforcement learning algorithm that directly optimizes the policy itself, policy gradient methods compute a estimator of the gradient and optimize it using the gradient ascent algorithm. Specifically, this estimator is generally:
where is the stochastic policy and is the estimator of the advantage function at timestep .
So the estimator is actually obtained by differentiating the objective:
However, directly using as a loss for optimization may lead to excessively large policy updates, potentially pushing the policy away from well-performing regions, and it often performs poorly in practice. Therefore, various methods such as PPO are typically used, as they incorporate mechanisms to control update sizes and ensure more stable and efficient learning.
Generalized Advantage Estimator(GAE)
GAE is a widely applicable advantage estimation method that can effectively reduce the variance of gradient estimation in policy gradient methods. The formula of GAE is:
High-Dimensional Continuous Control Using Generalized Advantage Estimation
TRPO(Trust Region policy optimization)
TRPO maximizes an objective function while subjecting it to a constraint on the size of the policy update. Specifically:
subject to , where, is the policy parameters before the update.
By incorporating a penalty term in the objective function to control the size of policy updates, the problem becomes an unconstrained optimization problem:
where is the coefficient. However, experiments show that using a fixed and optimizing the upper objective with SGD is insufficient, which leads to the development of PPO.
Methods
PPO(Proximal Policy Optimization)
PPO - CLIP
We define that , then the main objective proposed by PPO is:
where is the hyperparameter. This formulation ensures that remains within a certain range, preventing from deviating too much from .
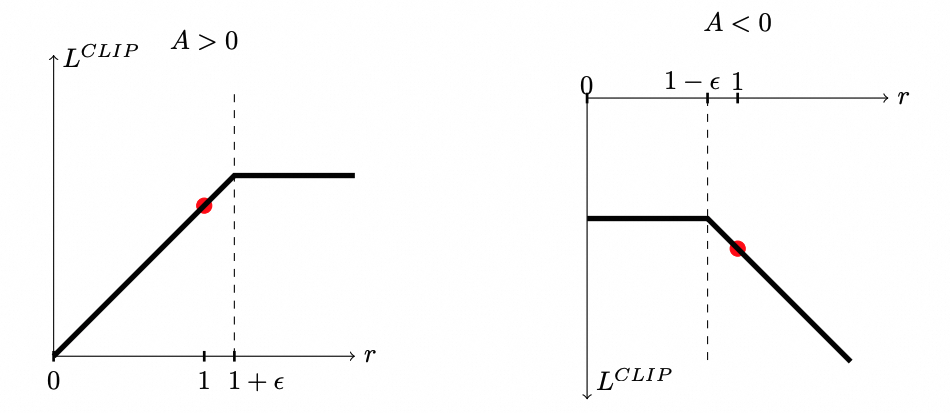
The choice between and depends on the sign of the advantage function .
When (i.e., the current action is better than the baseline):
Increasing (i.e., the new policy is more inclined to choose this action) will enhance the objective function because it amplifies the positive advantage. However, to prevent excessively large policy updates that could destabilize training, if , the clipped term will be smaller than the unclipped term . Since the objective function takes the minimum of the two, in this case, the clipped term will be selected, thereby ignoring further increases in that would otherwise beneficially change the objective.
When (i.e., the current action is worse than the baseline):
Decreasing (i.e., the new policy is less inclined to choose this action) will enhance the objective function because it reduces the impact of the negative advantage. If , the clipped term will be smaller than the unclipped term (since is negative). In this case, the clipped term will be selected, thereby preserving from decreasing too much.
In fact, the role of is to constrain the updates of within a certain range.
PPO - Penalty
PPO-penalty employs several epochs of minibatch SGD to optimize the KL-penalized objective given by:
then computes
- If ,
- If ,
where is a pre-set hyperparameter used to limit the difference between the current policy and the policy from the previous iteration. The updated is used for the next policy update.
Apparently, PPO-penalty imposes less strict constraints on the magnitude of policy updates compared to PPO-clip, and its performance in experiments is also inferior to the latter according to the PPO paper.
PPO’s Advantage Estimator
PPO adopts a truncated generalized advantage estimator(GAE), when :
where . In RLHF, is provided by the reward model, generally using the following formula:
is given by the critic model, which fits the expected return by calculating an MSE loss with the actual return .
DPO
High-Dimensional Continuous Control Using Generalized Advantage Estimation
Proximal Policy Optimization Algorithms
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
https://lilianweng.github.io/posts/2018-04-08-policy-gradient/