Last updated on December 15, 2025 pm
Infra: https://github.com/volcengine/verl
Train Data: https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k
Eval Data: https://huggingface.co/datasets/HuggingFaceH4/aime_2024
https://huggingface.co/datasets/HuggingFaceH4/MATH-500
Base Model: https://huggingface.co/Qwen/Qwen2.5-7B
https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
Prompt Template:
1 template = f"""Solve the following math problem step by step. The last line of your response should be of the form Answer: $Answer (without quotes) where $Answer is the answer to the problem.\n\n{question} \n\nRemember to put your answer on its own line after \"Answer:\".""" "
训练配置
首先对于Base模型,我们的配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 python3 -m verl.trainer.main_ppo --config-path=config \'ppo_megatron_trainer.yaml' \"$train_files " \"$test_files " \'error' \'console' ,'wandb' ] \'verl_grpo_dapo17k' \'qwen2_7b_base_use_kl_loss_megatron' \$@
其中lr为1e-6,来自verl官方的默认实现 ,没有warm_up以及decay,根据Qwen2.5 Technical Report,Qwen2.5-Base模型训练时的LR没有貌似具体说明(pretrain),但是SFT从7e-6开始decay到7e-7,offline RL(DPO)阶段的LR为7e-7,所以看起来1e-6也比较合理。
Qwen2.5 Technical Report
以下这些参数经过了调整,目前的配置可以在单机8卡(80G VRAM per GPU)上运行。
param
offical
mine
train_batch_size
1024
32
ppo_mini_batch_size
256
16
ppo_micro_batch_size_per_gpu
40
1
max_prompt_length
512
1024
max_response_length
1024
15360
rollout.n
5
3
rollout.gpu_memory_utilization
0.6
0.45
log_prob_micro_batch_size_per_gpu
40
1
显存占用应该来自三部分:训练时激活/KV Cache 占用 + vLLM KV + 模型权重/优化器
由于使用flash-attn,训练时激活显存 应该和KV Cache 一样,均为线性增长。官方配置中启动的模型上下文窗口应该是 2k (512 + 1024 ceil),而我修改后应该是16k,相当于8x增长,很容易OOM,因此我降低了ppo_micro_batch_size_per_gpu from 40 to 1, 相当于40x的降低,同时减少rollout.gpu_memory_utilization,给Actor分配更多的显存。
ppo_mini_batch_size在这里只影响收敛速度和稳定性,其实可以不用改。(as well as rollout.n)
此外,遵循verl官方的设置:
1 2 3 actor_rollout_ref.actor.use_kl_loss=True \
/verl/verl/workers/actor/megatron_actor.py
1 2 3 4 5 6 7 8 9 if self.config.use_kl_loss:"ref_log_prob" ]"actor/kl_loss" ] = kl_loss.detach().item()"actor/kl_coef" ] = self.config.kl_loss_coef
这里使用low_var_kl,也就是k3估计:
1 2 3 4 kl = ref_logprob - logprob1 ).contiguous()return torch.clamp(kld, min =-10 , max =10 )
最终的policy_loss 要加上k3估计的 kl_loss,kl_loss_coef为系数,这里使用0.001
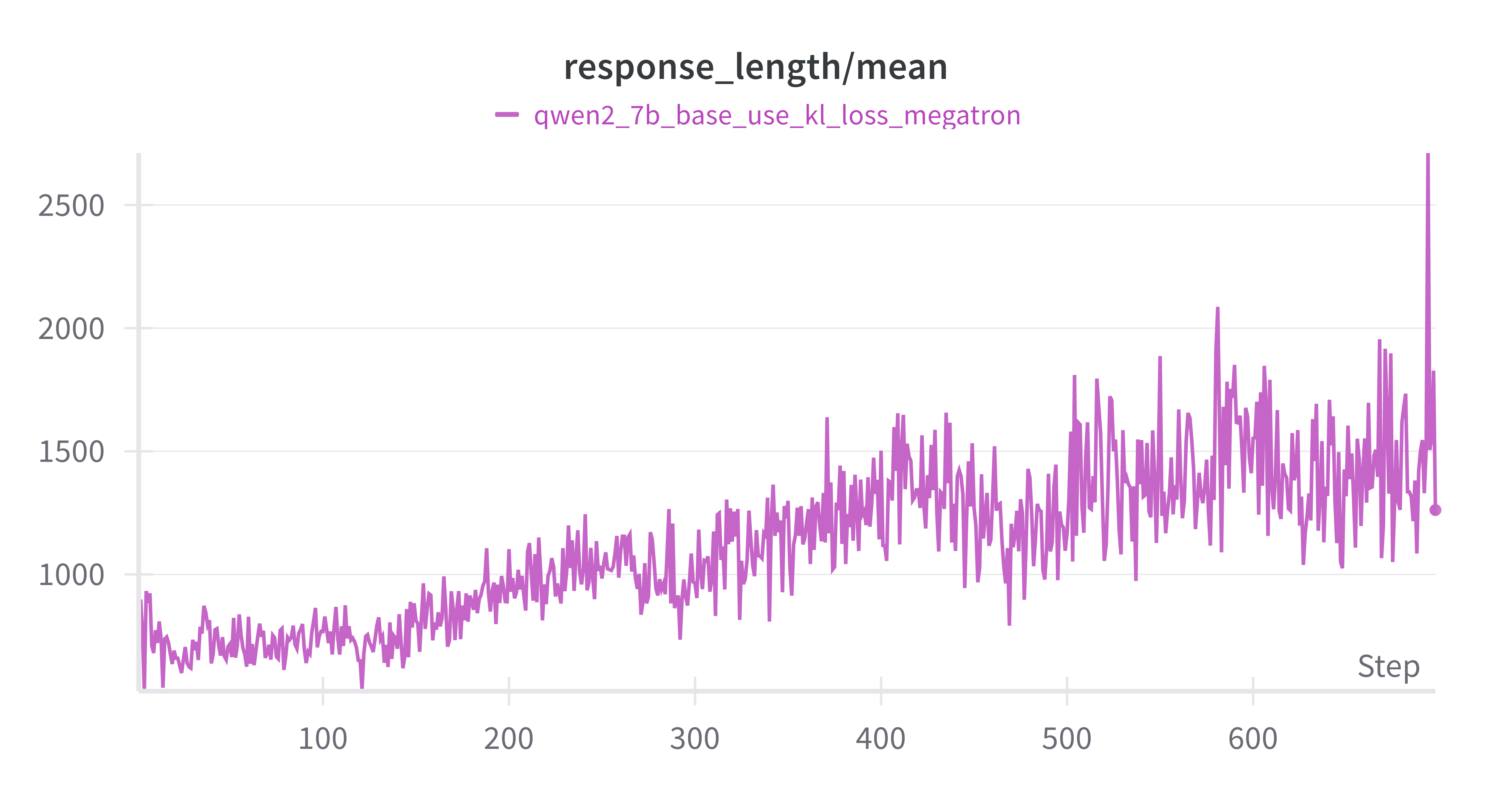
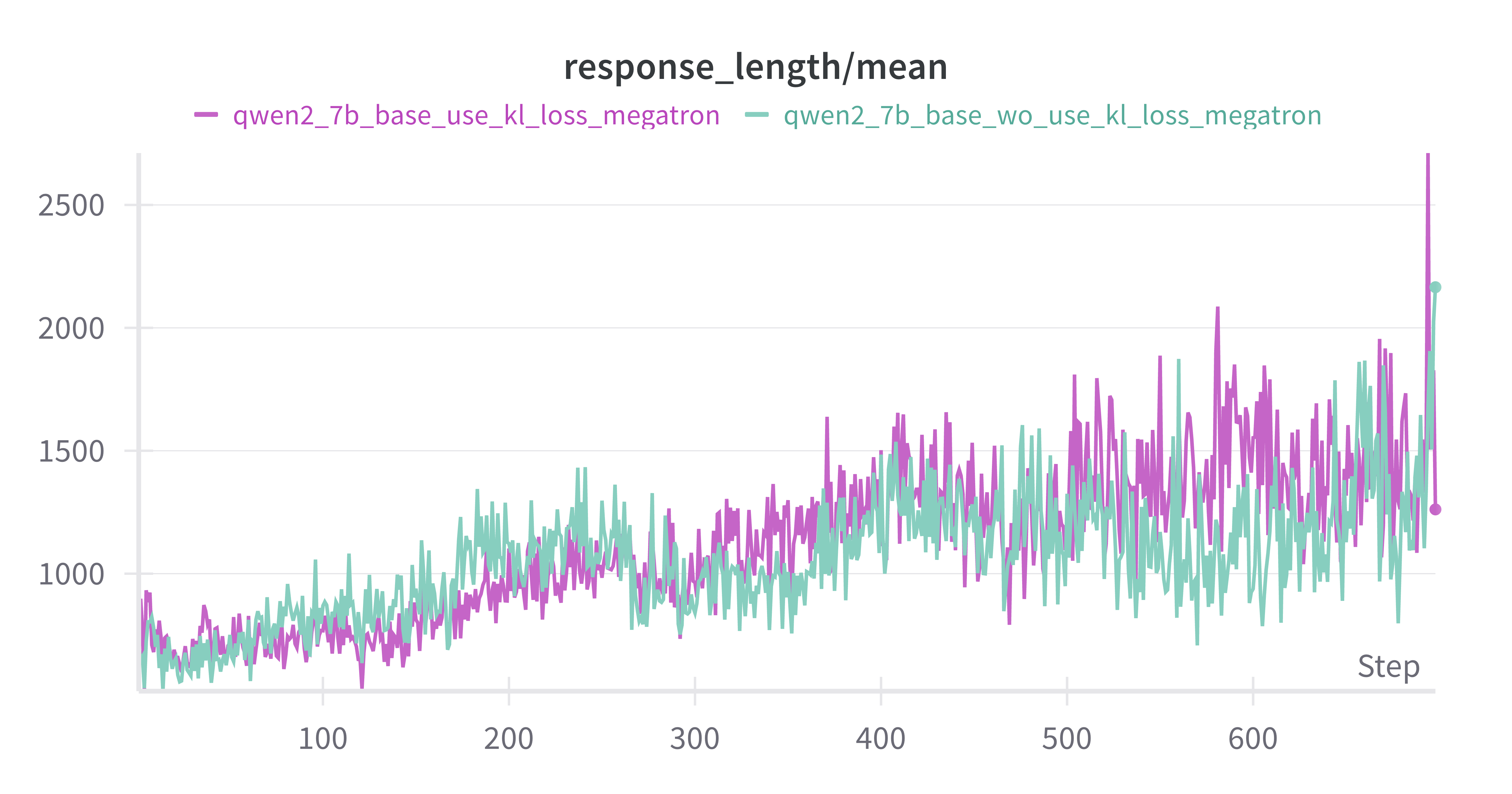
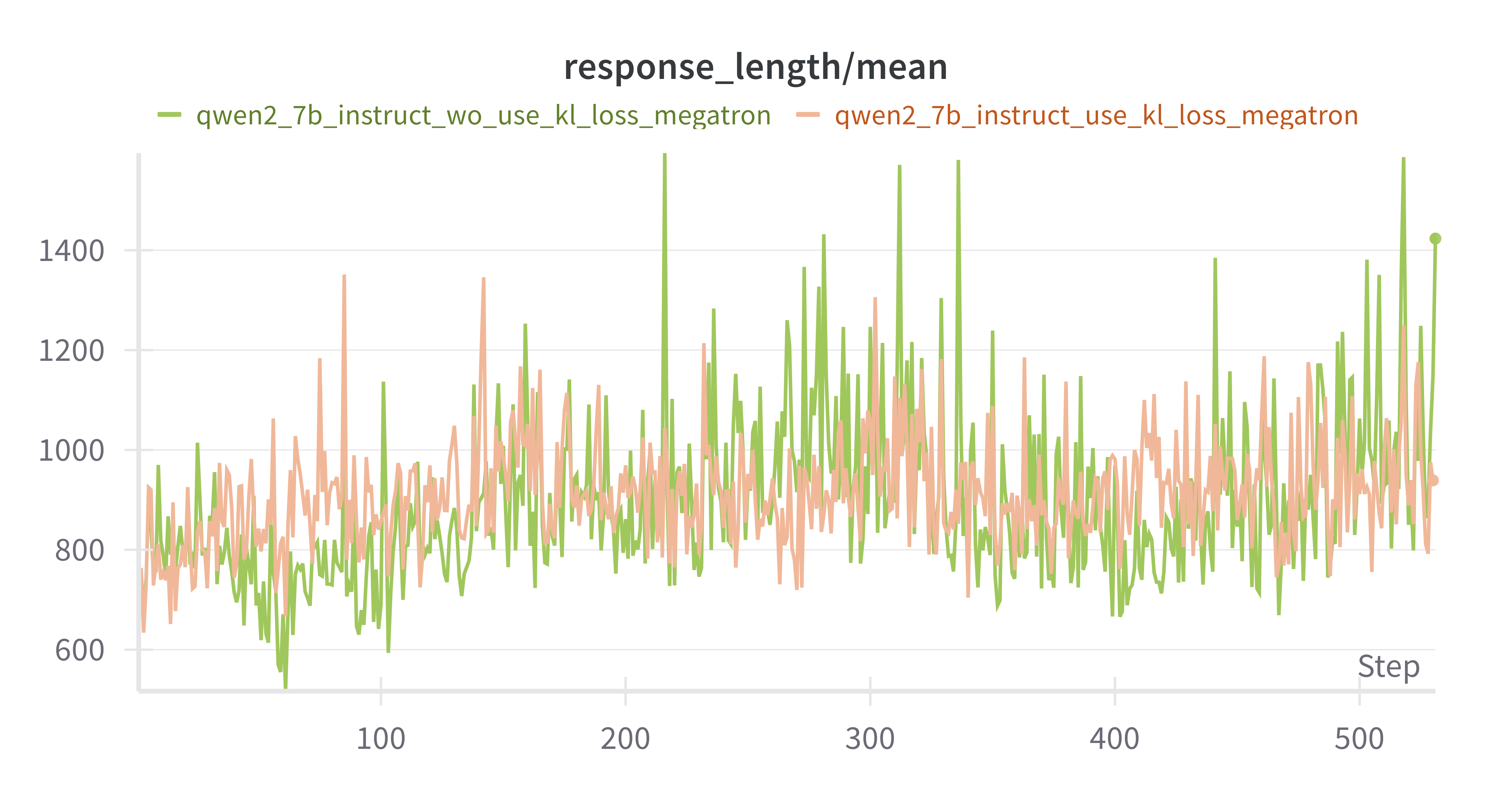
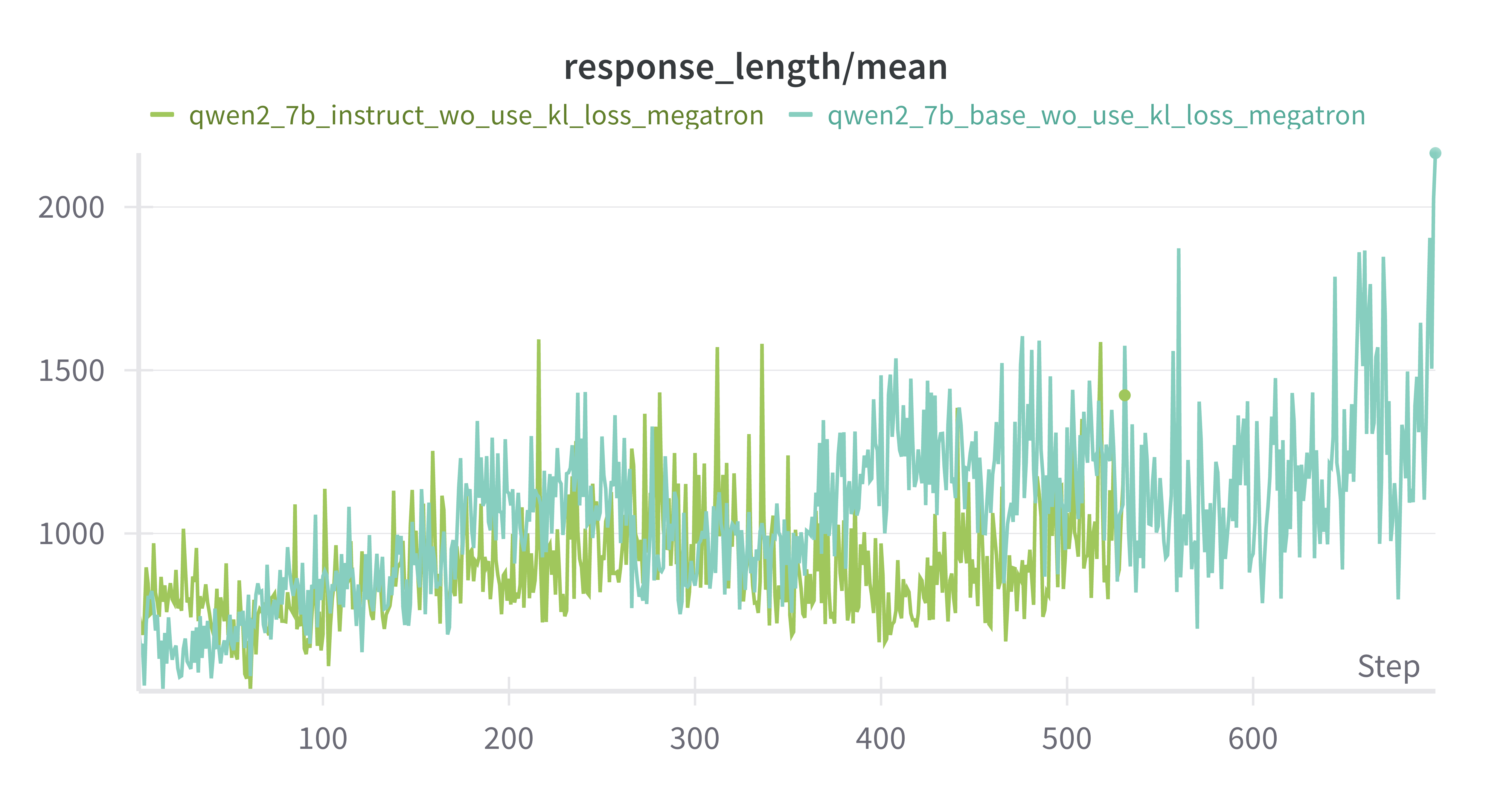
response length持续增加
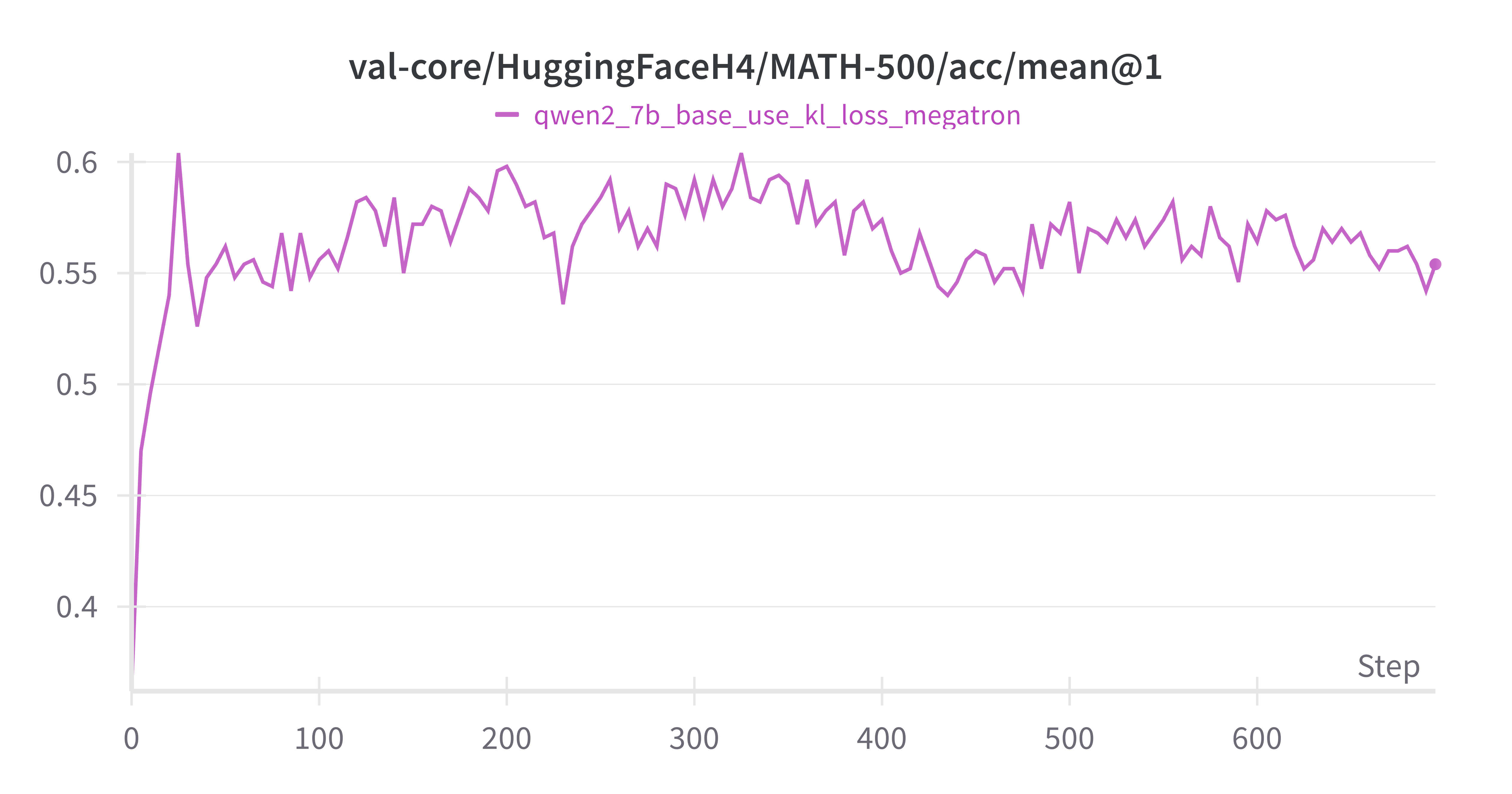
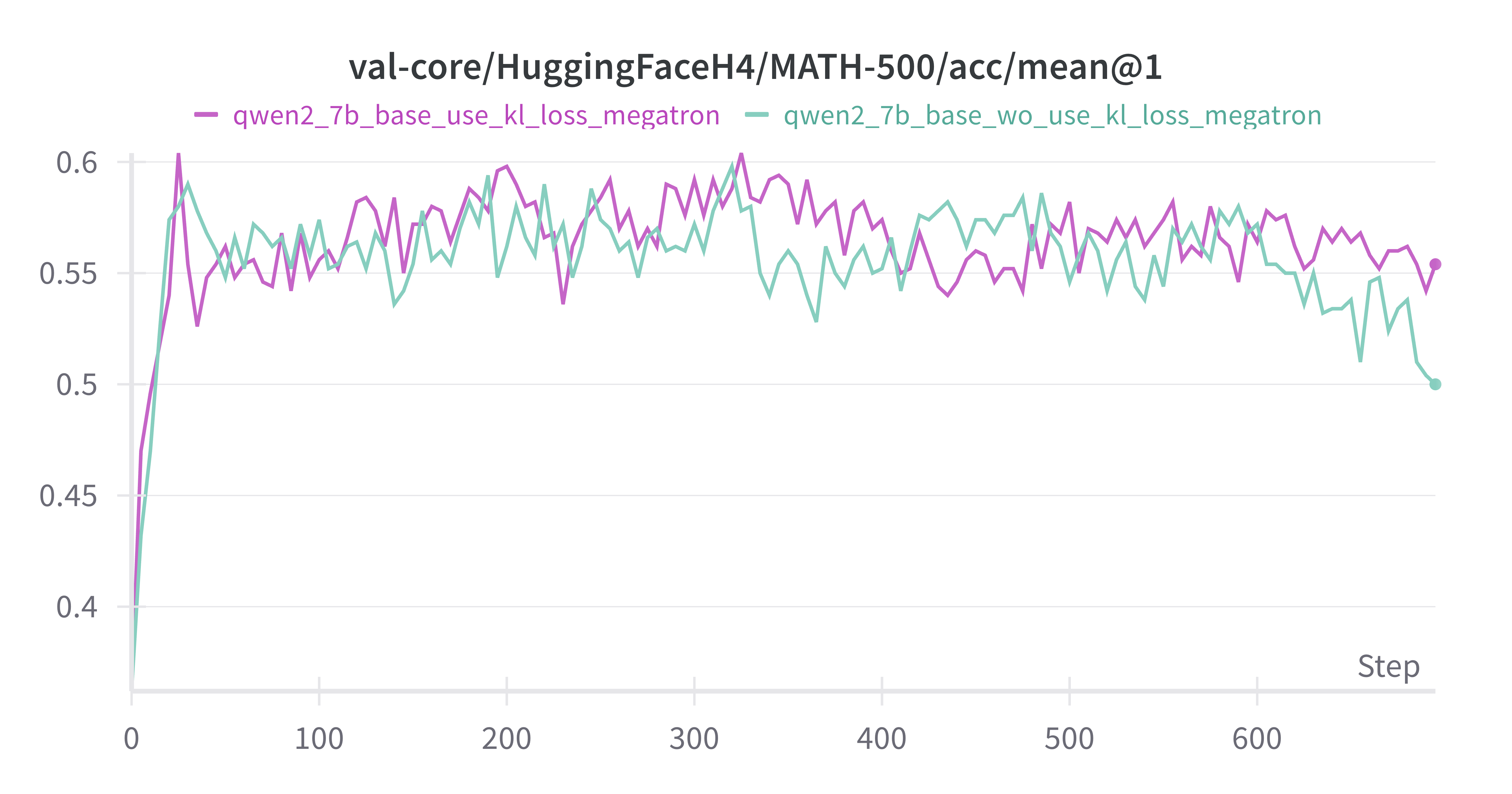
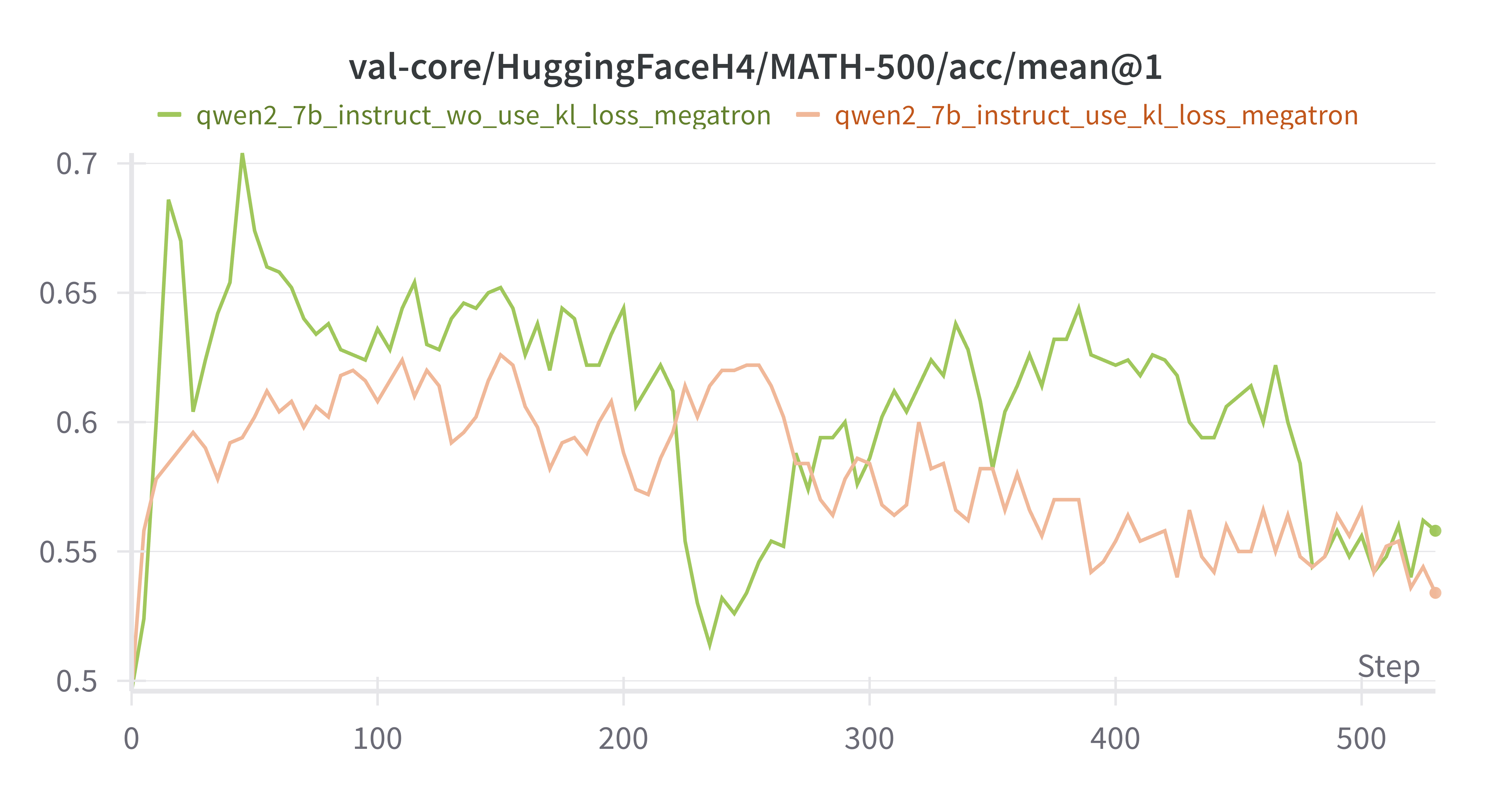
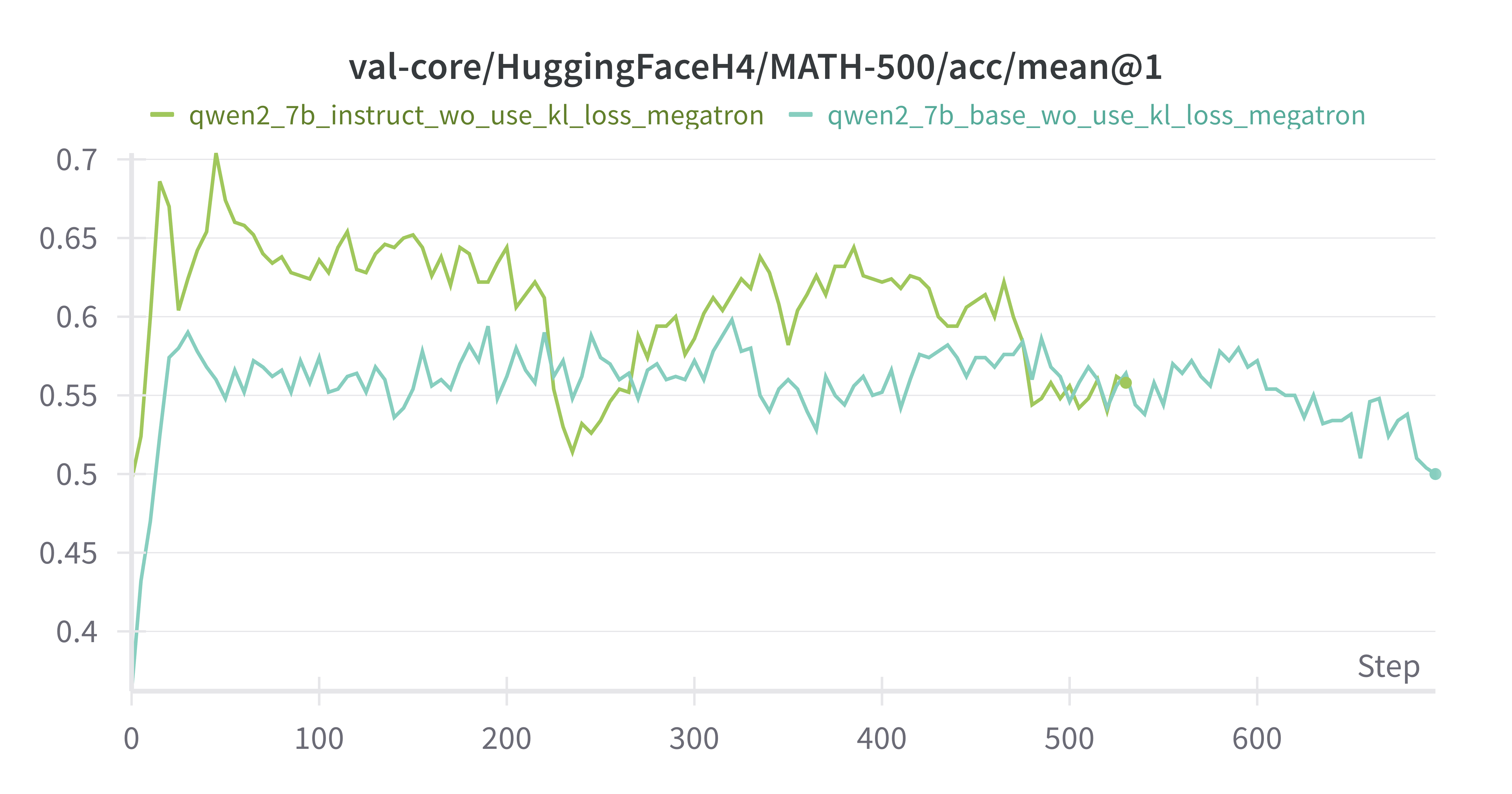
MATH-500 acc在前25个steps快速rise到ceiling,后续波动
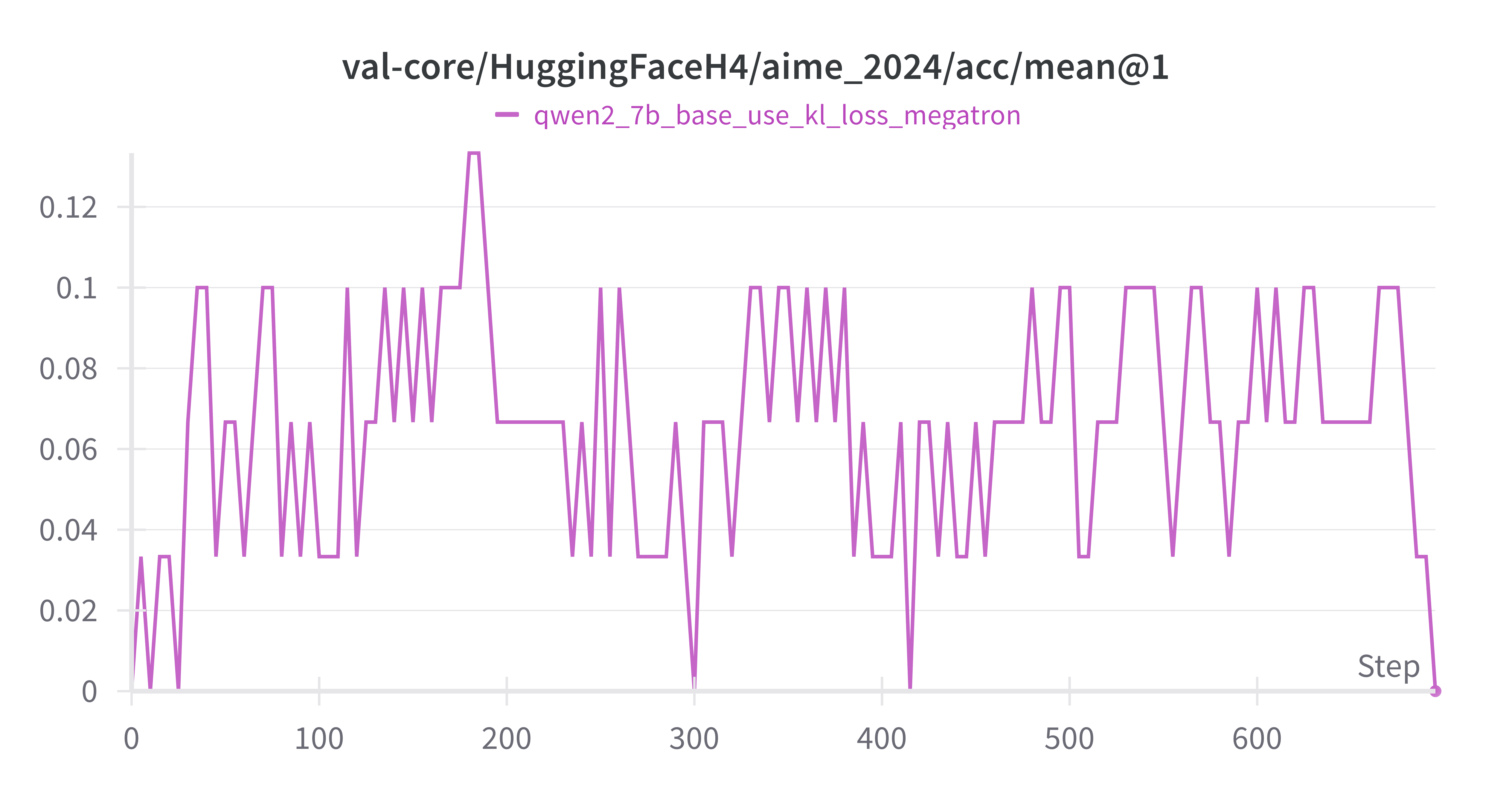
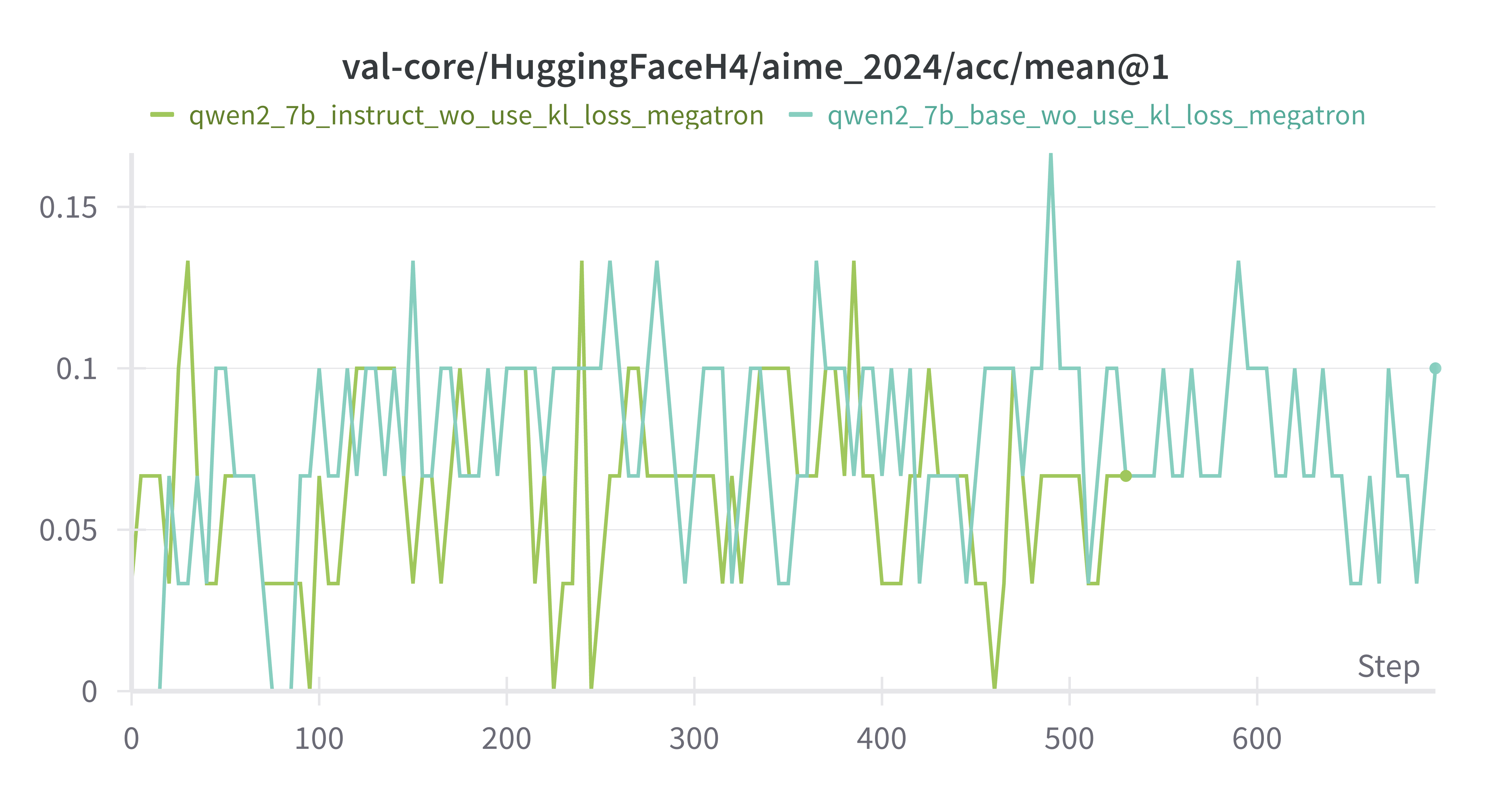
AIME-2024 持续波动
随训练step增加:
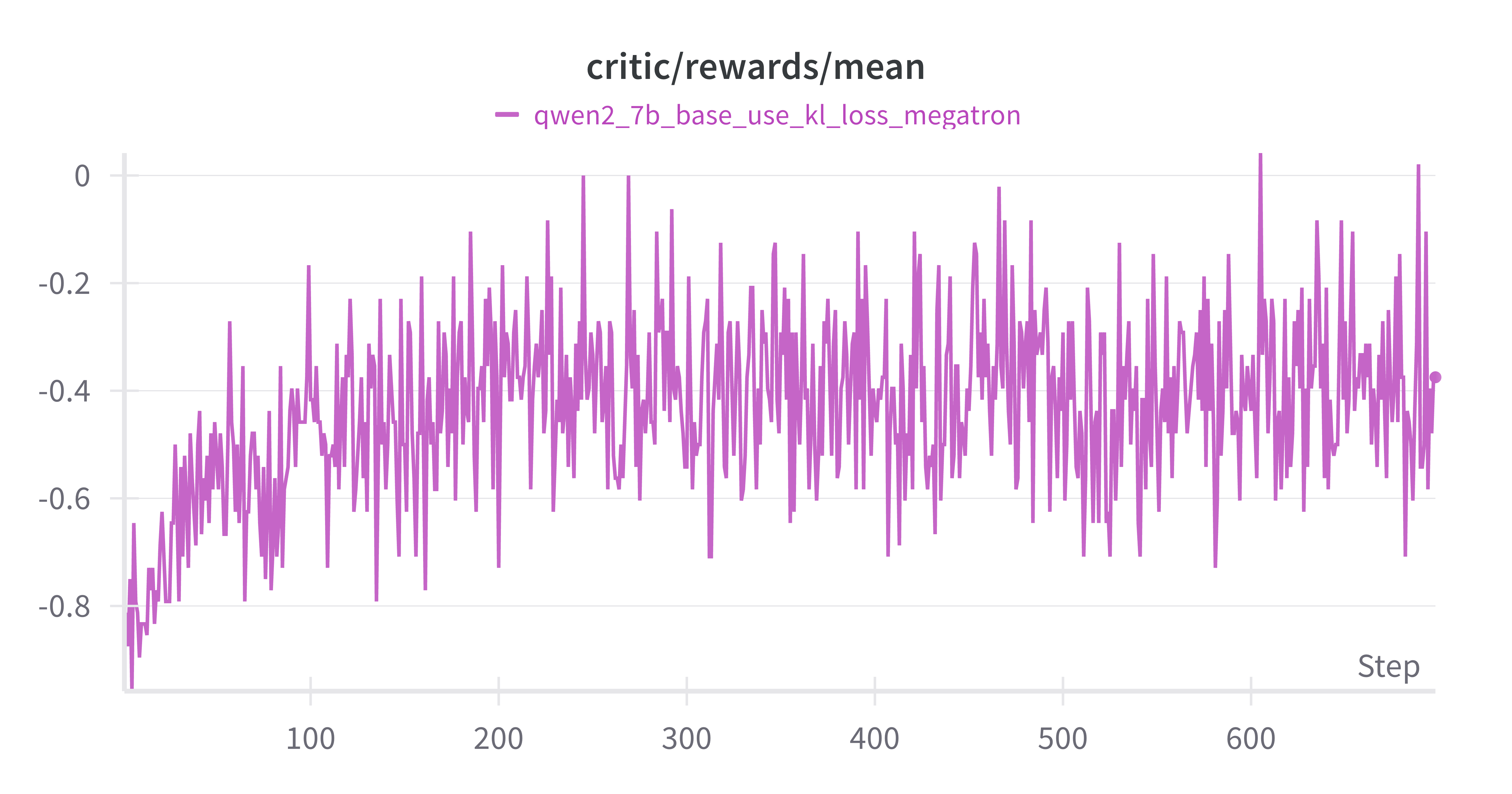
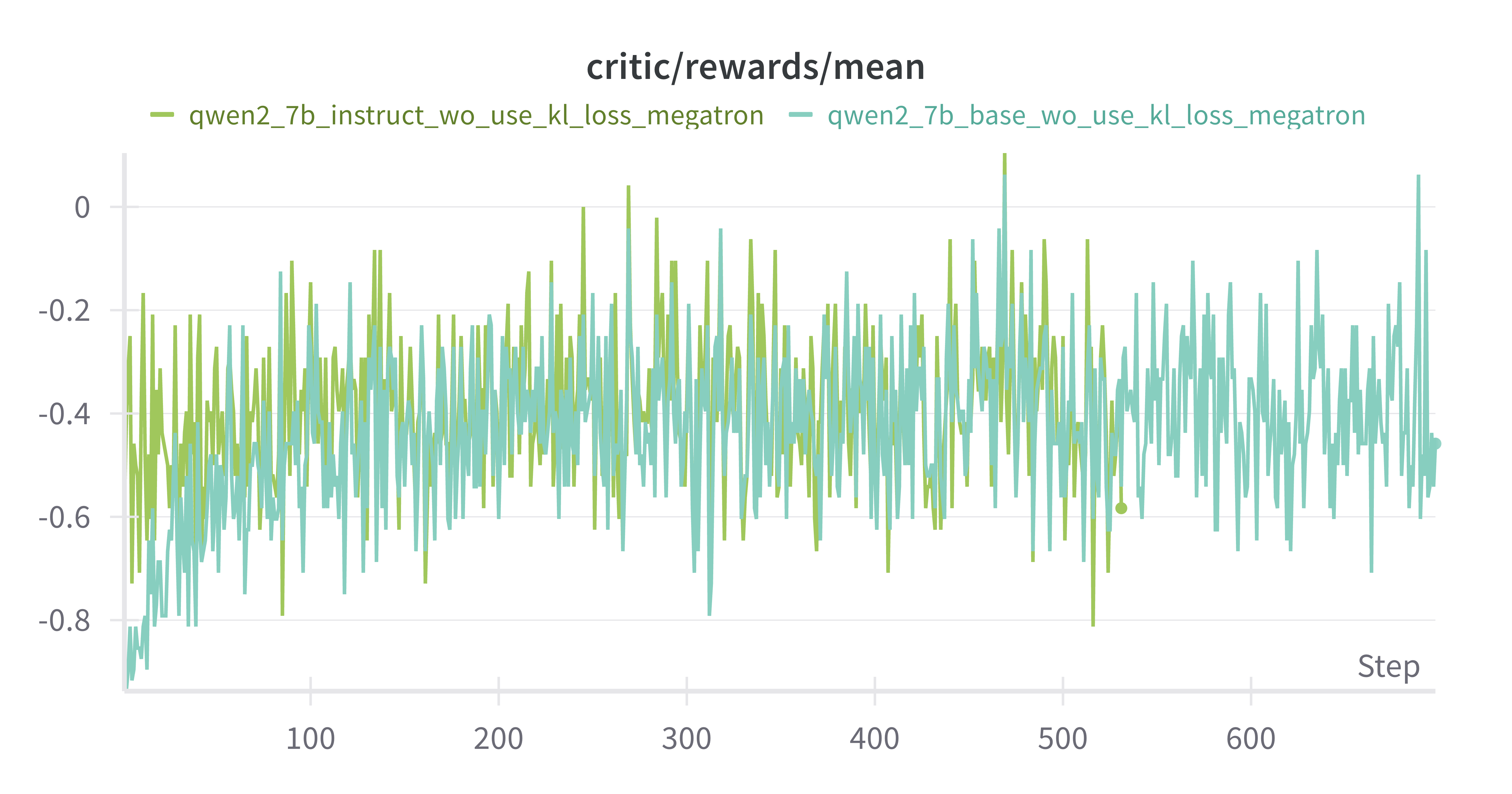
mean reward 增加:符合预期
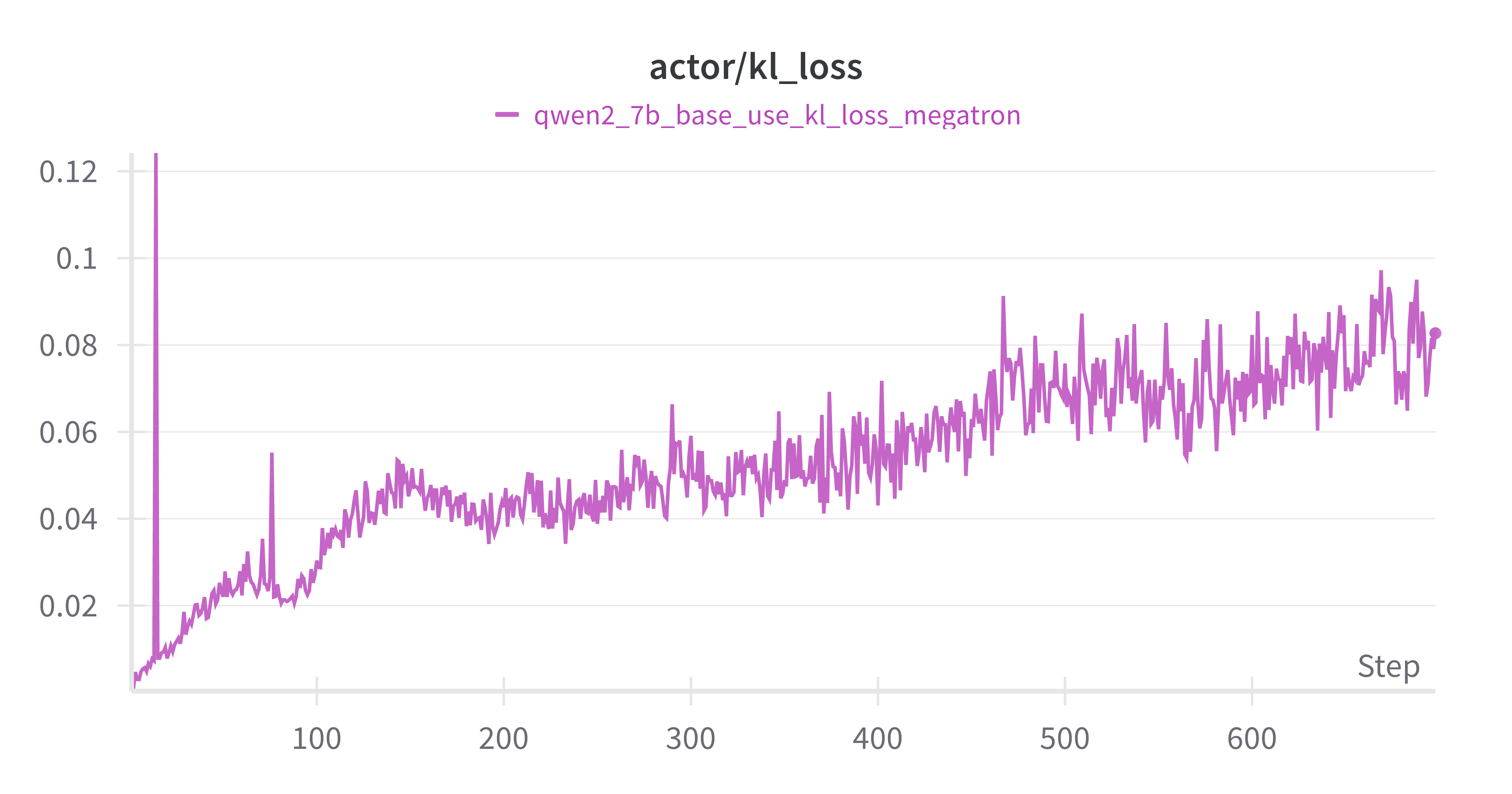
kl_loss增加:policy model 和 ref model 差异增大
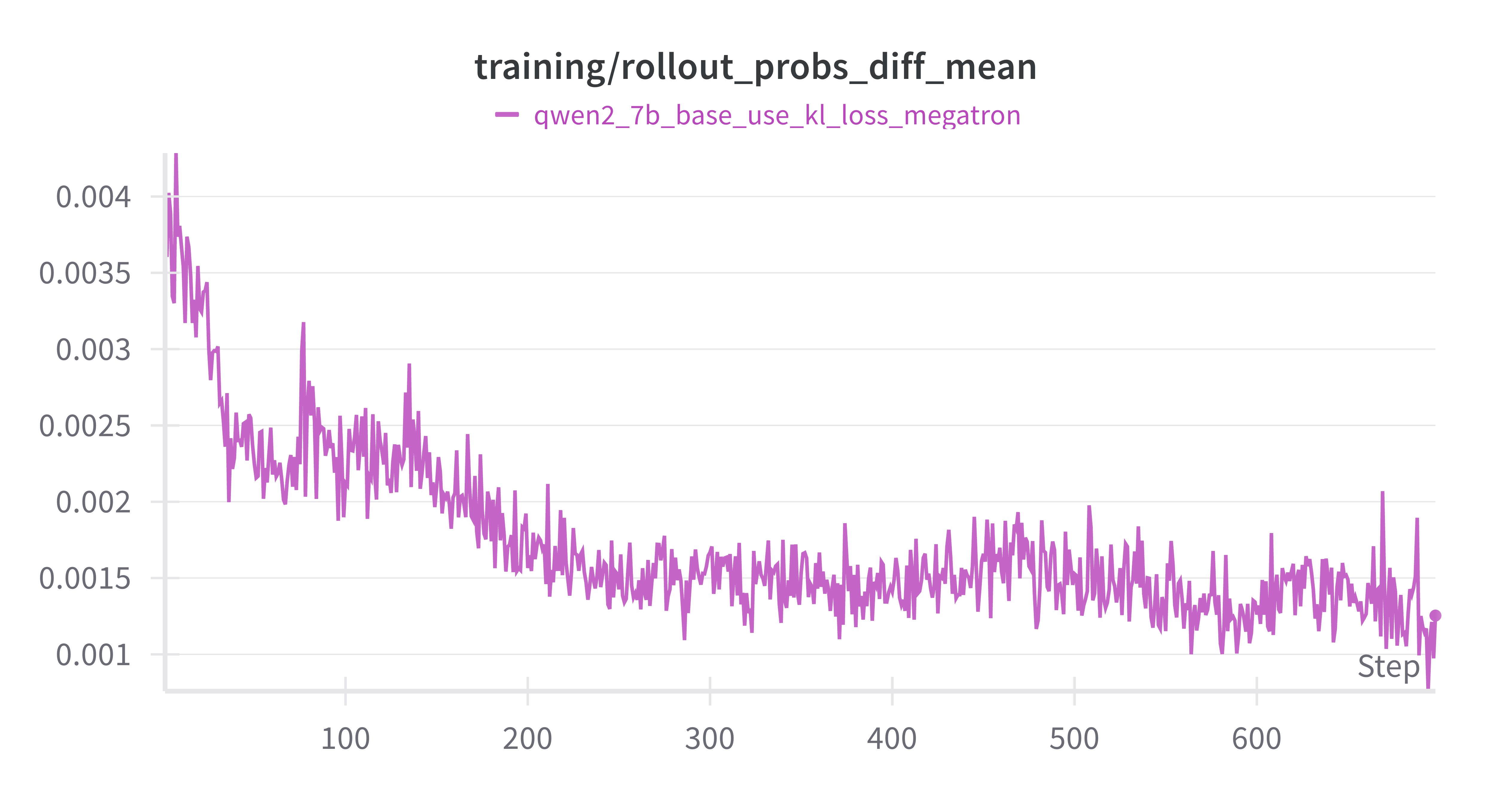
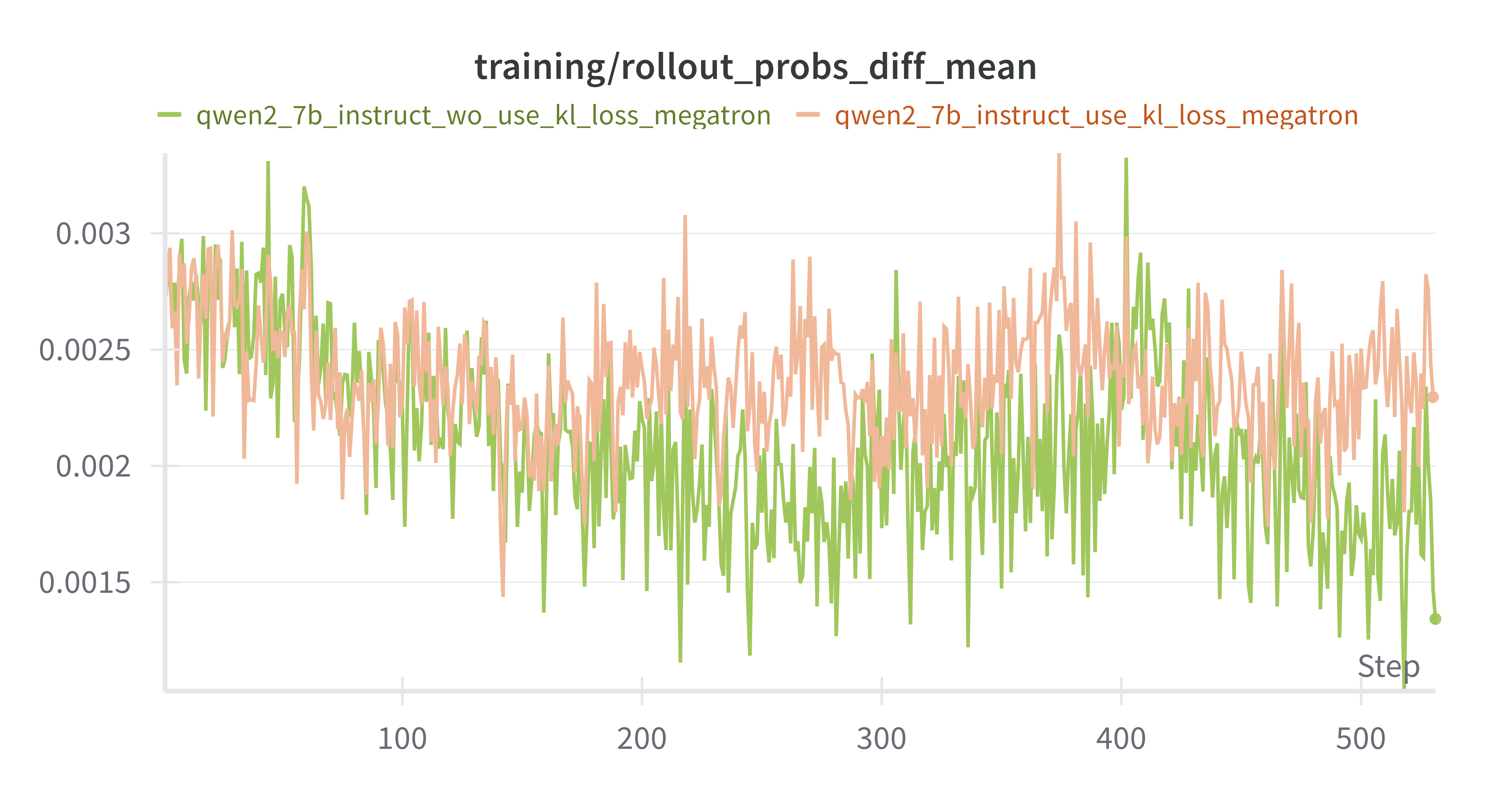
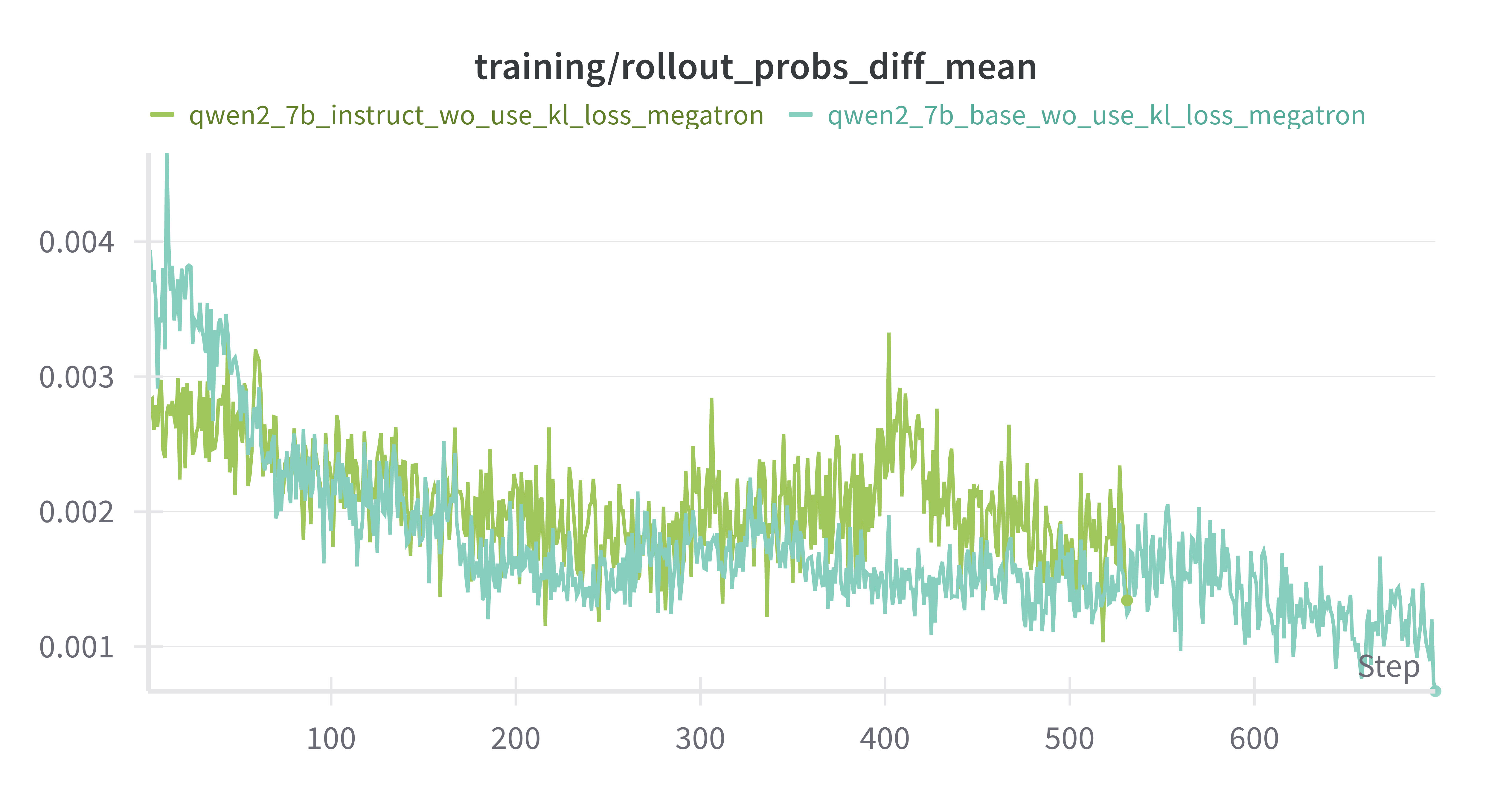
rollout_probs_diff_mean降低:policy model收敛
training/rollout_probs_diff_mean:
1 N tok ∑ t = 1 N tok ∣ p actor ( t ) − p rollout ( t ) ∣ , \frac1{N_\text{tok}}\sum_{t=1}^{N_\text{tok}}
\bigl|\,p_{\text{actor}}^{(t)}-p_{\text{rollout}}^{(t)}\bigr|,
N tok 1 t = 1 ∑ N tok p actor ( t ) − p rollout ( t ) ,
——当前 Actor 对batch内 每个 token 的概率 p actor p_\text{actor} p actor 生成当时缓存的概率 p rollout p_\text{rollout} p rollout 绝对差 的平均值
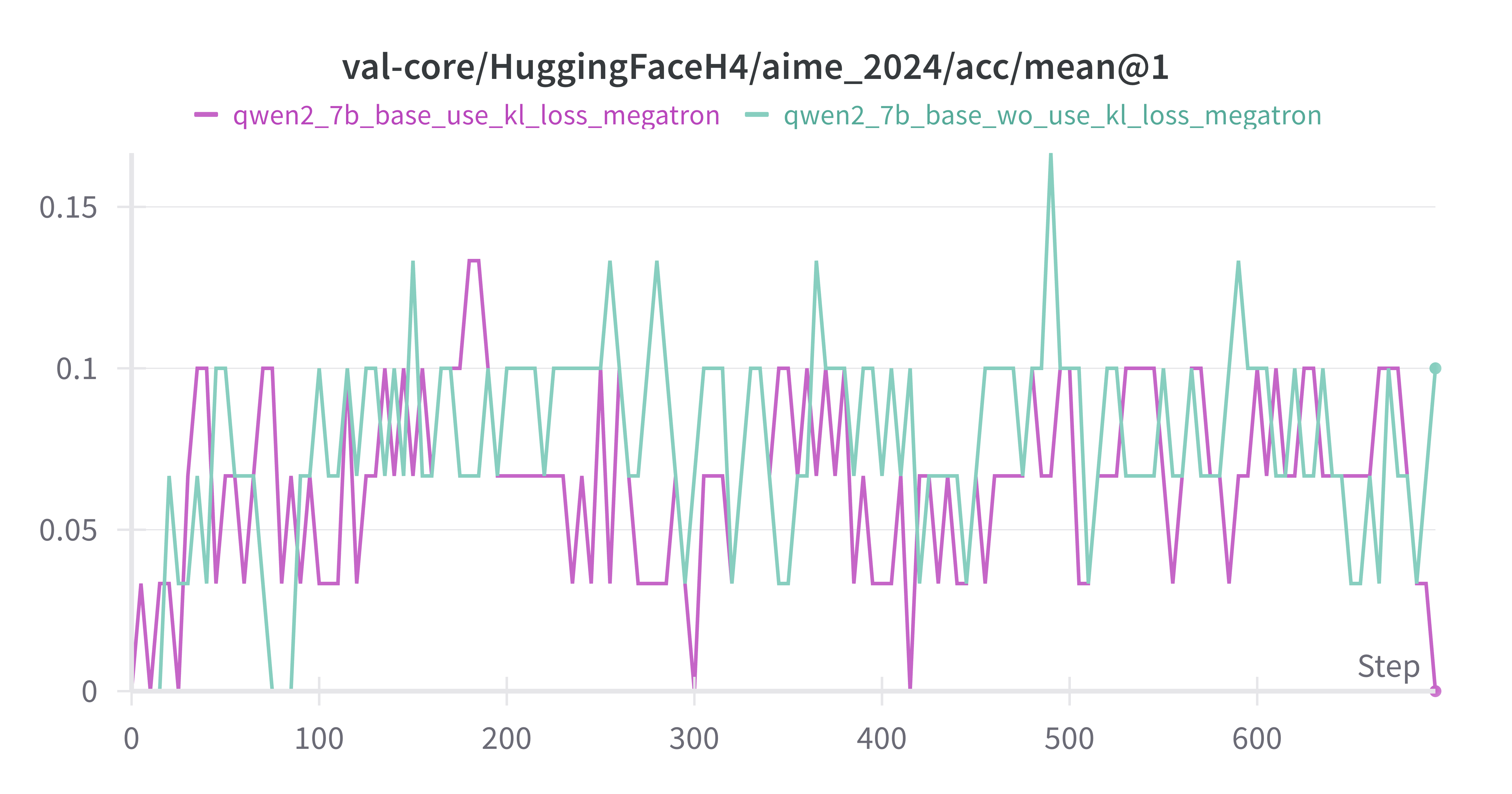
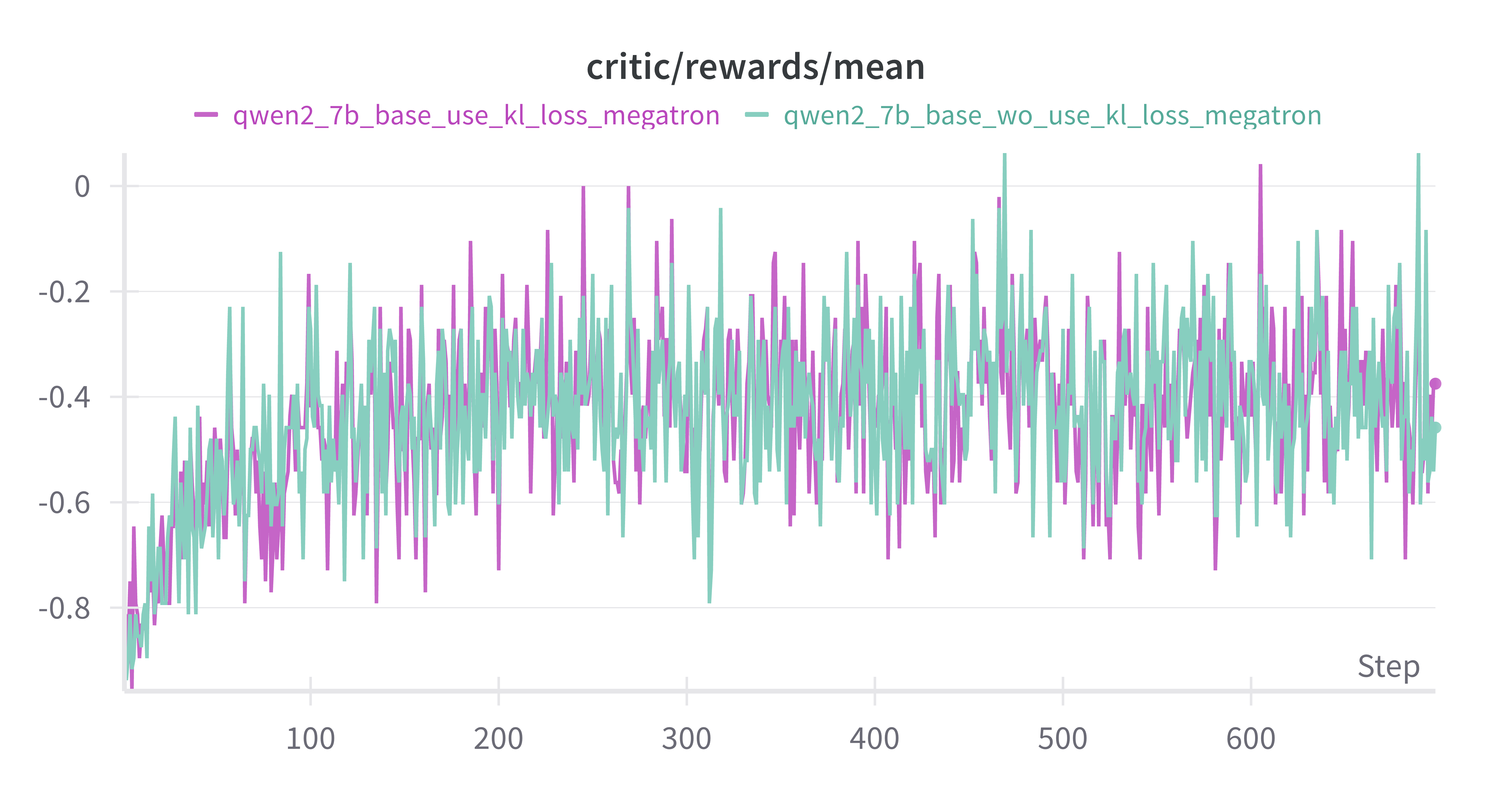
w/ vs w/o kl_loss on Base Model
设置actor.kl_loss_coef=0 & 0.001,紫色为w/ kl_loss,蓝绿色为w/o kl_loss
差异不大,推测是actor.kl_loss_coef=0.001太小了
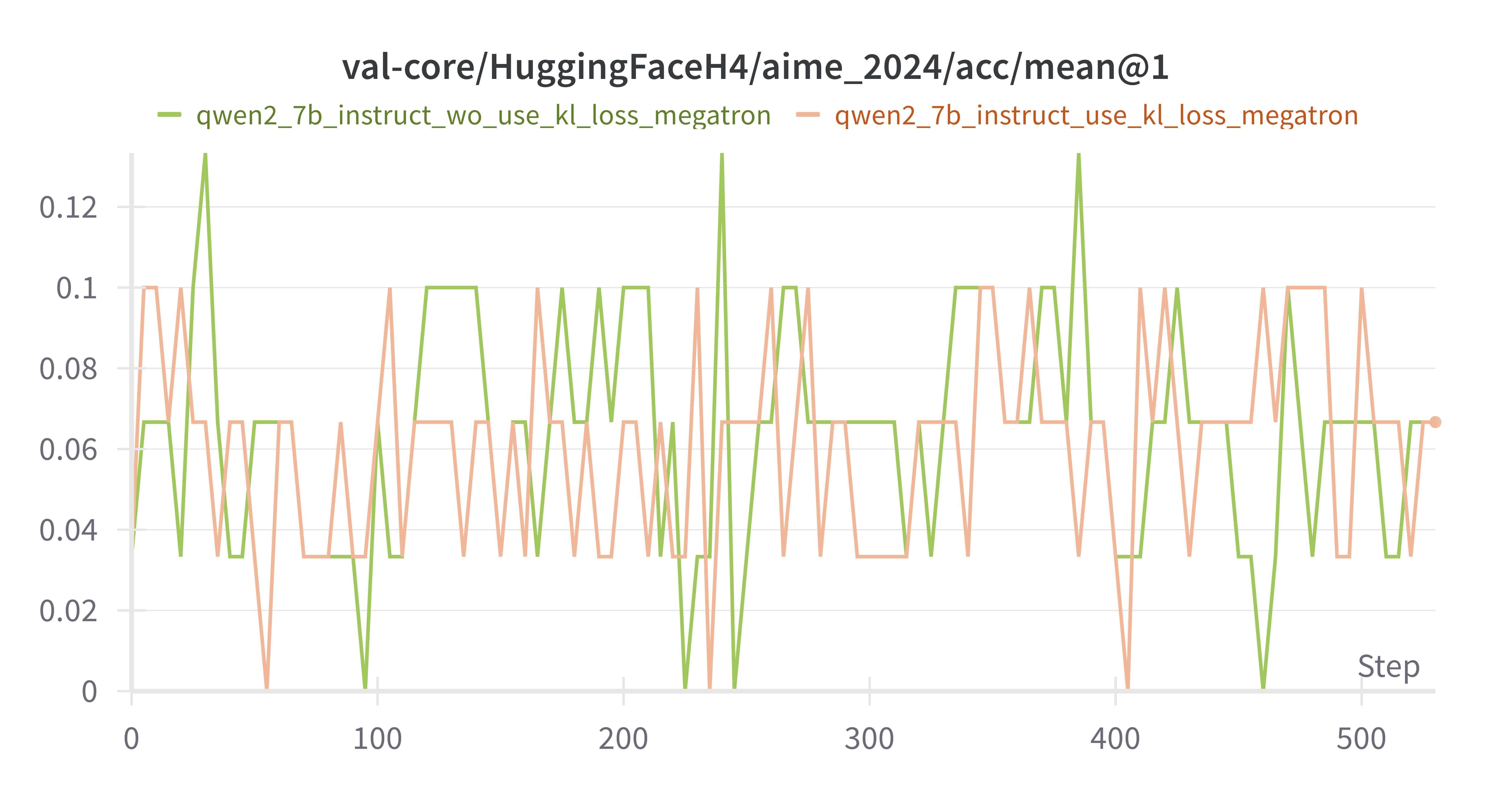
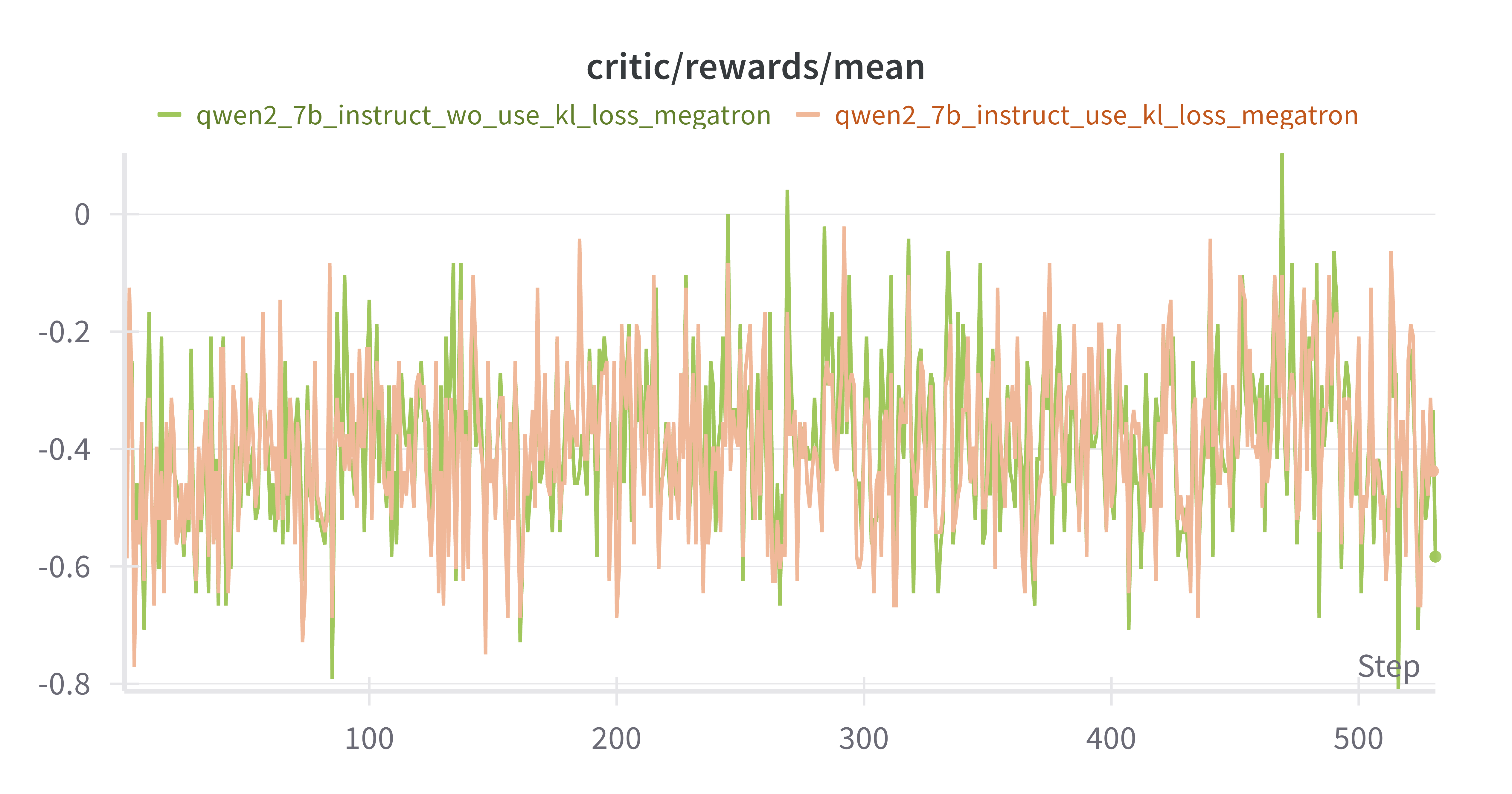
w/ vs w/o kl_loss Instruct Model
设置actor.kl_loss_coef=0 & 0.01,橙色为w/ kl_loss,绿色为w/o kl_loss
mean response_length差别不是很大,训练后期w/o kl_loss出现超长response的情况更多MATH-500上 w/o kl_loss上限更高,但是更不稳定AIME-2024 差别不大critic/reward/mean 差别不大training/rollout_probs_diff_mean上,w/o kl_loss 150 steps后更低
Base Model vs Instruct Model (both w/o kl_loss)
Instruct模型最开始时reward更高
其余差别不是很大(可能是评测集展现不出差别,按理来说base模型多样性更高,上限更高)