Verl
Last updated on January 8, 2026 pm
Change Log:
- 2026-01-08: Initial release of the article.
Online-RL
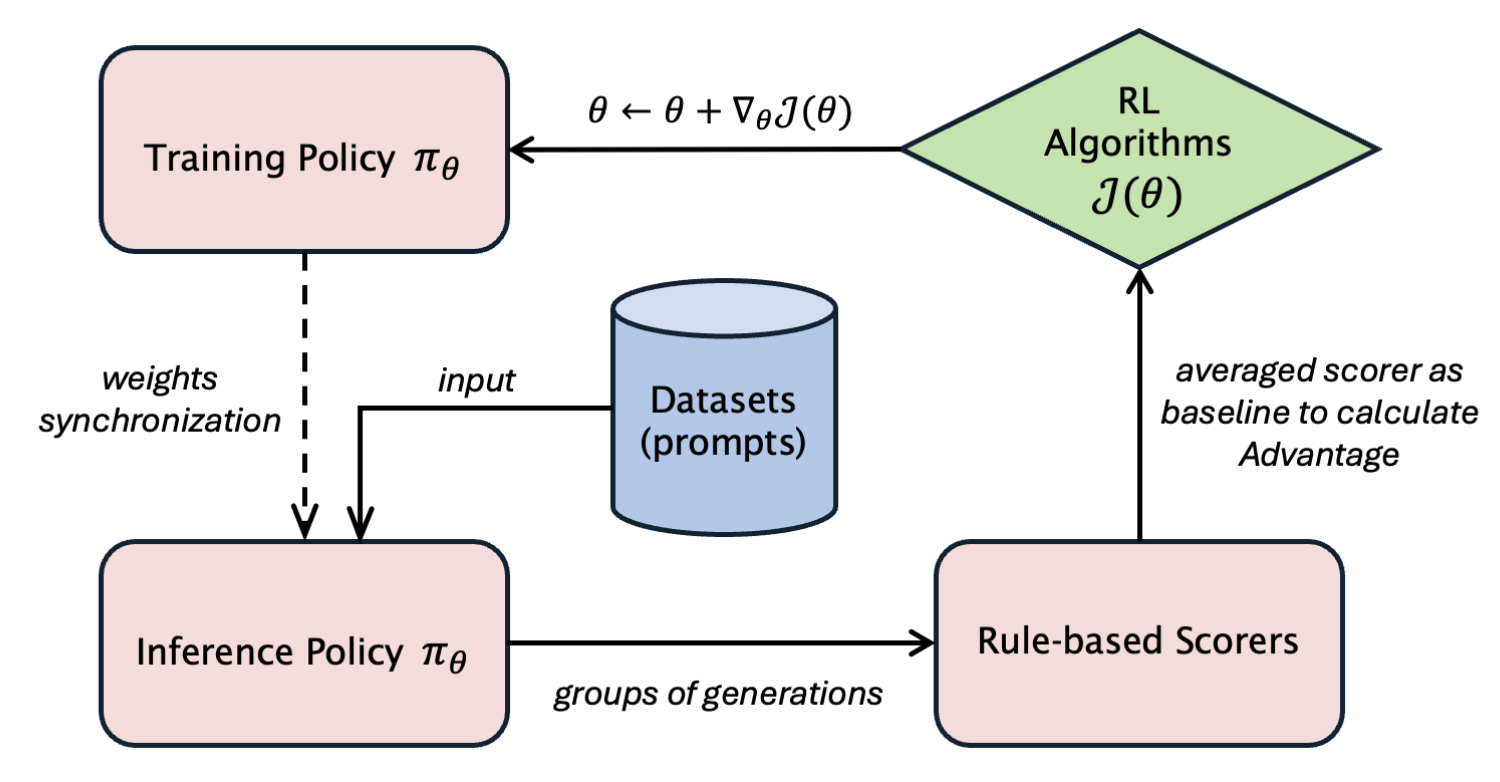
上图是online-rl的简化流程图,省略了ref model 和 critic model
从verl入手,我们分析一下online-rl训练过程中,各个role的显存占用情况,以及目前已有的加速方案
不考虑critic model的情况下,我们一般有三个模型要加载:
- reference model_1,用于rollout阶段进行轨迹的rollout,是上一个step的policy model,一般用vllm / sglang部署,以加速rollout
- reference model_2,用于logprob的重计算,由于vllm/sglang精度的问题,rollout阶段算出来的logprob不太准,为了重采样时更加准确,因此要用hf加载,计算准确的logprob_ref
- 只有当需要计算kl或者需要重要性采样的时候才会加载
- actor model,策略模型,根据策略梯度公式进行梯度更新,也需要计算logprob_policy
这三个模型在verl上默认是分阶段加载的,也可以理解为时分复用,顺序就是按照介绍顺序
对于单机8卡来说,假设使用vllm进行rollout,fsdp作为多卡训练引擎,以一个7b模型为例:
rollout
在rollout的时候有这样的几个参数控制分片:
- tensor_model_parallel_size
- pipeline_model_parallel_size
- data_parallel_size
- 默认是1,不用修改,vllm内部会自动计算真正的data_parallel_size
在fsdp构建rollout mesh的时候,计算逻辑是:
- infer_tp = tensor_model_parallel_size * data_parallel_size
- infer_pp = pipeline_model_parallel_size
- infer_world_size = infer_tp * infer_pp
- dp = world_size // infer_world_size
8卡时world_size=8,假如设置:
- tensor_model_parallel_size=4
- pipeline_model_parallel_size=1
那么:
- infer_tp = 4 * 1 = 4
- infer_world_size = 4 * 1 = 4
- dp = 8 / 4 = 2
- mesh = (dp=2, infer_tp=4, infer_pp=1)
也就是说,会有两个并行的vllm推理副本,分别占据4张卡
finish rollout
在rollout阶段结束的时候,也就是generate_sequences调用结束,pipeline会进入到trainer_mode,如果设置了rollout.free_cache_engine=True,那么对于vllm rollout而言,会reset_prefix_cache,vllm进程进入sleep状态,从而将kv_cache 和权重都卸载掉,具体卸载实现需要看vllm的实现。不过可以确定的是,GPU显存会得到释放
rollout.free_cache_engine一般默认是True,默认进行显存的释放
ref logprob re-compute
fsdp包裹的hf模型进行logprob计算,默认的actor_rollout_ref.actor.fsdp_config.fsdp_size=-1,相当于fsdp=world_size,也就是默认FULL_SHARD across world_size,在整个world_size上对模型参数进行分片,对于7b模型来说,通信开销非常大,尤其是多机多卡的时候,比如8机64卡
对于7b模型而言,单卡h100 80G显存就绰绰有余,因此actor_rollout_ref.actor.fsdp_config.fsdp_size设置为1可能更合适一点
设置为1时,计算ref model的logprob的时候,采用的是dp=world_size,速度相对较快
update actor
同样是fsdp包裹hf进行参数更新,规则和ref logprob re-compute基本一样,同样通过actor_rollout_ref.actor.fsdp_config.fsdp_size来控制分片,默认-1,也就是模型参数分布在64卡上
和ref不同的是,actor会进行梯度更新,也就是会进行后向传播,如果actor_rollout_ref.actor.fsdp_config.fsdp_size设置为1的话,那么首先显存压力会大一些,不过对于7b模型 来说,也不会大太多,同时反向传播会走all-reduce梯度,相比于-1时(可能走的是all-gather+reduce-scatter),速度也不一定更快,所以看起来actor_rollout_ref.actor.fsdp_config.fsdp_size维持默认值比较合适,具体需要试验一下
how to accelerate training stage?
在多机多卡场景下,比如8机64卡,如何对训练进行加速呢?vllm rollout
- 尽可能提高gpu gpu_memory_utilization,增加可用的kv-cache,一般设置为0.9~0.95
- 尽可能用小的tensor_parallel_size,比如7b模型就可以用tensor_parallel_size=1,从而尽可能增加vllm 副本,提高rollout时的数据并行度
- log_prob_micro_batch_size_per_gpu在避免oom的情况下尽可能大
- use_dynamic_bsz=True
但是上面的调优其实都是在verl这种同步架构上面继续压榨潜力,实际上目前社区已经有一些异步的架构了,比如AReal,可能对于多机规模上去后同步等待严重的问题有一定的缓解
https://hebiao064.github.io/rl-memory-management
https://verl.readthedocs.io/en/latest/perf/perf_tuning.html
https://verl.readthedocs.io/en/latest/perf/nsight_profiling.html
AREAL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning